Processing 11 million rows in minutes instead of hours
Written on 2026-01-19Before you start: I just published a second part of this blog post, you can read it here.
Around 5 years ago, I decided to drop all client-side analytics on this blog, and instead opt for server-side anonymous analytics. I had several reasons:
- No more client-side overhead by removing JavaScript libraries
- Actually respecting my audience's privacy
- More accurate metrics because around 50% of visitors block client-side trackers
- Finally, it was a fun challenge for me
The architecture is pretty straight forward: there's a long-running script on my server monitoring this blog's access log. It filters out crawlers and bot traffic, and stores real traffic in a database table. Since I want to generate graphs with this data, I opted to use event sourcing. Each visit is stored in the database, and that historic data is then processed by multiple projectors. Each projector generates a unique interpretation of that data. For example, there's a projector for the number of visits per day, one for the number of visits per month, one of the most popular posts this week, etc.
The biggest upside of using event sourcing is that I can always add new projectors after the fact and rebuild them from the same historic data set. That rebuilding feature is exactly the performance problem I was optimizing this week. After five years, I've accumulated over 11 million visits on this blog. The code powering this system, however, was still running a very outdated Laravel installation. It was high time to convert it to Tempest, and to also fine-tune some of the older graphs.
After copying those 11 million rows to the new database, I'd have to rebuild all projectors from scratch; the first time I'd be doing this since the start of the project. Doing so, I ran into a pretty significant performance issue: the replay command — the command that replays historic events — processed around 30 events per second per projector, so replaying those 11 million rows for a dozen or so projectors would take… around 50 hours. Yeah, I wasn't going to wait around that long. Here's what happened next.
Establishing a baseline
Whenever I want to debug a performance issue, my first step is to set a baseline: the situation as it is right now. That way, I can actually measure improvements. My baseline is straightforward: 30 events per second. Here's what the replay command looks like that I used to generate that baseline — I did strip away all the metric calculations, setup code, and added some comments for clarity:
final readonly class EventsReplayCommand { #[ConsoleCommand] public function __invoke(?string $replay = null): void { // Setup and metrics work, I've hidden this part foreach ($projectors as $projectorClass) { // We only run the selected projectors if (! in_array($projectorClass, $replay, strict: true)) { continue; } // We resolve a projector from the container $projector = $this->container->get($projectorClass); // Then we clear all its contents // to rebuild it from scratch $projector->clear(); // We loop over all events, // sorted from old to new, chunked per 500 StoredEvent::select() ->orderBy('createdAt ASC') ->chunk( function (array $storedEvents) use ($projector): void { foreach ($storedEvents as $storedEvent) { // Each event is replayed on the projector $projector->replay($storedEvent->getEvent()); } }, 500, ); } // And we're done! } }
Again: I've stripped the irrelevant parts so that you can focus on the code that matters. Our baseline of 30 events per second absolutely sucks, but that's exactly what we want to improve! Now the real work can start.
No more sorting
A first step was to remove the sorting on createdAt ASC. Think about it: these events are already stored in the database sequentially, so they are already sorted by time. Especially since createdAt isn't an indexed column, I guessed this one change would already improve the situation significantly.
// We loop over all events, // sorted from old to new, chunked per 500 StoredEvent::select() ->orderBy('createdAt ASC') ->chunk(
Indeed, this change made our throughput jump from 30 to 6700 events per second. You would think that's the problem already solved, but we'll actually be able to more than triple that result in the end.
Reversing the loop
The next step doesn't really have a significant impact when running a single projector, but it does when running multiple ones. Our loop currently looks like this:
// Loop over each projector foreach ($projectors as $projector) { StoredEvent::select() ->orderBy('createdAt ASC') ->chunk( function (array $storedEvents) use ($projector): void { // Loop over each event foreach ($storedEvents as $storedEvent) { // … } }, 500, ); } }
There's an obvious issue here: we'll retrieve the same events over and over again for each projector. Since events are the most numerous (millions of events compared to dozens of projectors), it makes a lot more sense to reverse that loop:
StoredEvent::select() ->orderBy('createdAt ASC') ->chunk( function (array $storedEvents) use ($projectors): void { // Loop over each projector foreach ($projectors as $projector) { // Loop over each event foreach ($storedEvents as $storedEvent) { // … } } }, 500, );
Because my baseline was scoped to one projector, I didn't expect to gain much from this change. Still, I made sure it also didn't negatively impact my already established improvement. It didn't: it went from 6.7k to 6.8k events per second.
Ditch the ORM
The next improvement would again be a significant leap. Because we're dealing with so many events, it's reasonable to assume the ORM would be a bottleneck. As a test, I switched to a raw query builder instead. It required a bit more manual mapping, but the results were significant:
StoredEvent::select() query('stored_events') ->select() ->chunk(function (array $data) use ($projectors) { // Manually map the data to event classes $events = arr($data) ->map(function (array $item) { return $item['eventClass']::unserialize($item['payload']); }) ->toArray(); // Loop over each projector foreach ($projectors as $projector) { // Loop over each event foreach ($storedEvents as $storedEvent) { // … } } )};
A jump from 6.8k to 7.8k events per second! Not unsurprisingly. I have no objection to using an ORM for convenience, but convenience always comes at a cost. Dealing with these amounts of data, I rather reduce as many layers as possible to stay as close to the database as possible.
Even more decoupling
Having seen such an improvement by ditching the ORM, I wondered if removing the chunk() method which uses closures, and replacing it with a normal while loop would have an impact. Again a little more manual work was required, but…
$offset = 0; $limit = 1500; query('stored_events')->chunk( while ($data = query('stored_events')->select()->offset($offset)->limit($limit)->all()) { // Manually map the data to event classes $events = arr($data) ->map(function (array $item) { return $item['eventClass']::unserialize($item['payload']); }) ->toArray(); // Loop over each projector foreach ($projectors as $projector) { // Loop over each event foreach ($storedEvents as $storedEvent) { // … } } $offset += $limit; }
These changes improved performance from 7.8k to 8.4k events per second. Another small adjustment you might have noticed is that I adjusted the limit size from 500 to 1500. Trying out multiple options in my environment, this yielded the best result.
Faster serialization?
Because I want to store all kinds of events and not necessarily only page visits, the actual event data is serialized in the database. That's why we have to unserialize it like so:
$events = arr($data) ->map(function (array $item) { return $item['eventClass']::unserialize($item['payload']); })
I wondered whether there would be any improvements if I manually created a new event instead of unserializing an existing one. In the old Laravel version, event data was stored directly in a visits table, which meant I could access that data directly as well, for testing:
while ($data = query('visits')->select()->offset($offset)->limit($limit)->all()) { $events = arr($data) ->map(function (array $item) { return new PageVisited( url: $item['url'], visitedAt: new \DateTimeImmutable($item['date']), ip: $item['ip'], userAgent: $item['user_agent'] ?? '', raw: $item['payload'], ); }) ->toArray(); // … }
Surprisingly, though, this change had a negative impact. I reckon PHP's unserialization might be extra optimized. So I decided to not go this route. At this point, I wondered whether I had reached the limit. I wanted to be sure, though, that there were no bottlenecks left. So I decided to boot up the good ol' Xdebug and ran a profiler session.
Discovering a framework bug
Running the profiler, I saw something odd:
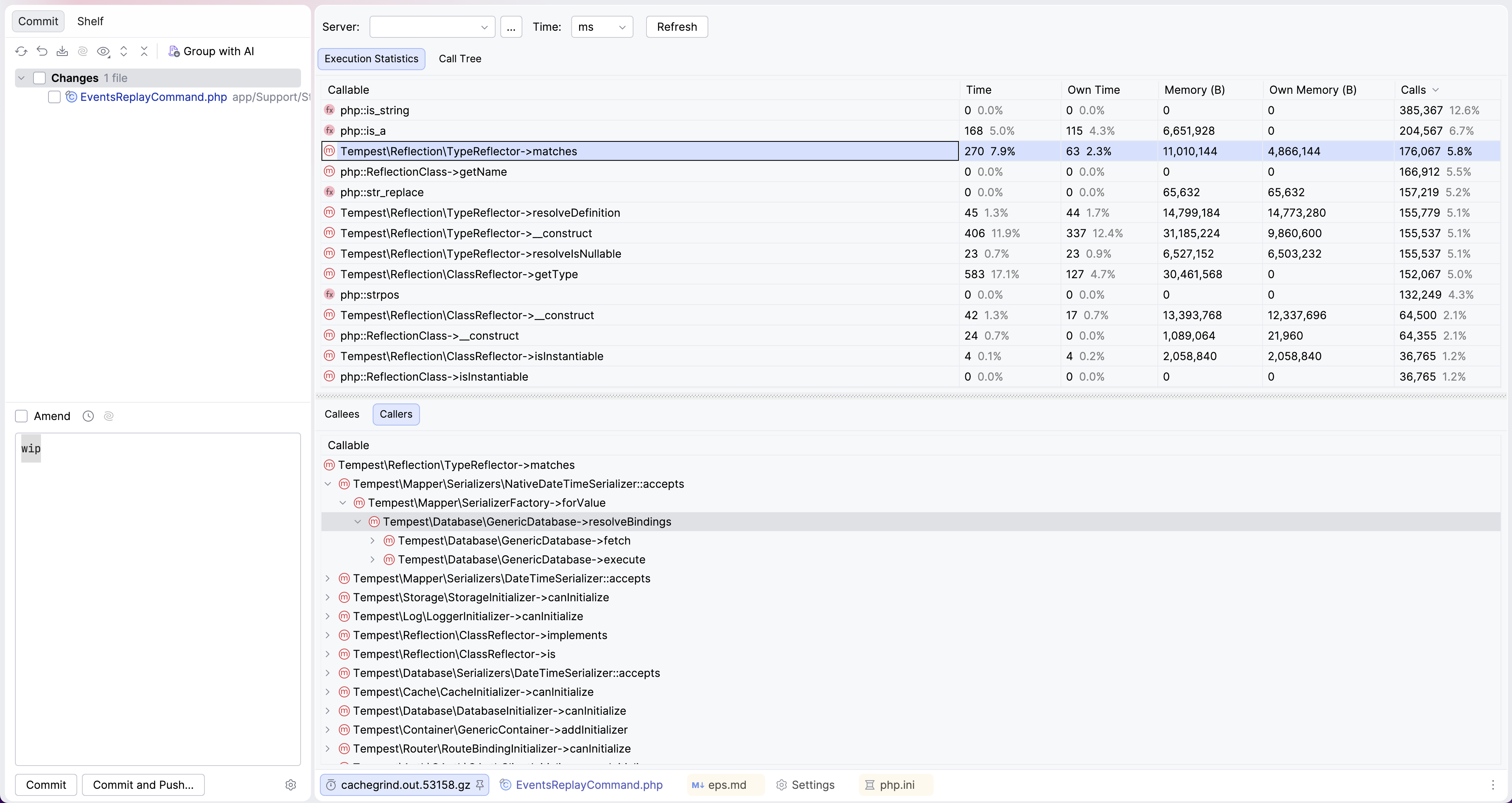
For one iteration, or in other words, 1.5k events; Tempest was calling TypeReflector 175k times. Now, this is a wrapper class around PHP's reflection API, which is heavily used in the ORM. But I already removed the ORM, didn't I? First, I checked whether the projector itself might still be using the ORM, but that wasn't the case:
final readonly class VisitsPerYearProjector implements Projector { // … #[EventHandler] public function onPageVisited(PageVisited $pageVisited): void { $date = $pageVisited->visitedAt->format('Y') . '-01-01'; new Query(<<<SQL INSERT INTO `visits_per_year` (`date`, `count`) VALUES (?, ?) ON DUPLICATE KEY UPDATE `count` = `count` + 1 SQL, [ $date, 1 ])->execute(); } }
What could it then be? Of course, the profiling data showed the culprit: GenericDatabase itself was using the SerializerFactory to prepare data before inserting it into the database. This factory uses reflection to determine what kind of serializer should be used for a given value:
private function resolveBindings(Query $query): array { $bindings = []; $serializerFactory = $this->serializerFactory->in($this->context); foreach ($query->bindings as $key => $value) { if ($value instanceof Query) { $value = $value->execute(); } elseif ($serializer = $serializerFactory->forValue($value)) { $value = $serializer->serialize($value); } $bindings[$key] = $value; } return $bindings; }
However, in our case, we know we're dealing with scalar data already, and we're certain our data won't need any serialization. That was an easy fix on the framework level:
if ($value instanceof Query) { $value = $value->execute(); } elseif (is_string($value) || is_numeric($value)) { // Keep value as is } elseif ($serializer = $serializerFactory->forValue($value)) { $value = $serializer->serialize($value); }
This small change actually got the most impressive improvement: performance jumped from 8.4k to 14k events per second!
Running another profiler session also confirmed: there were no more big bottlenecks to see!
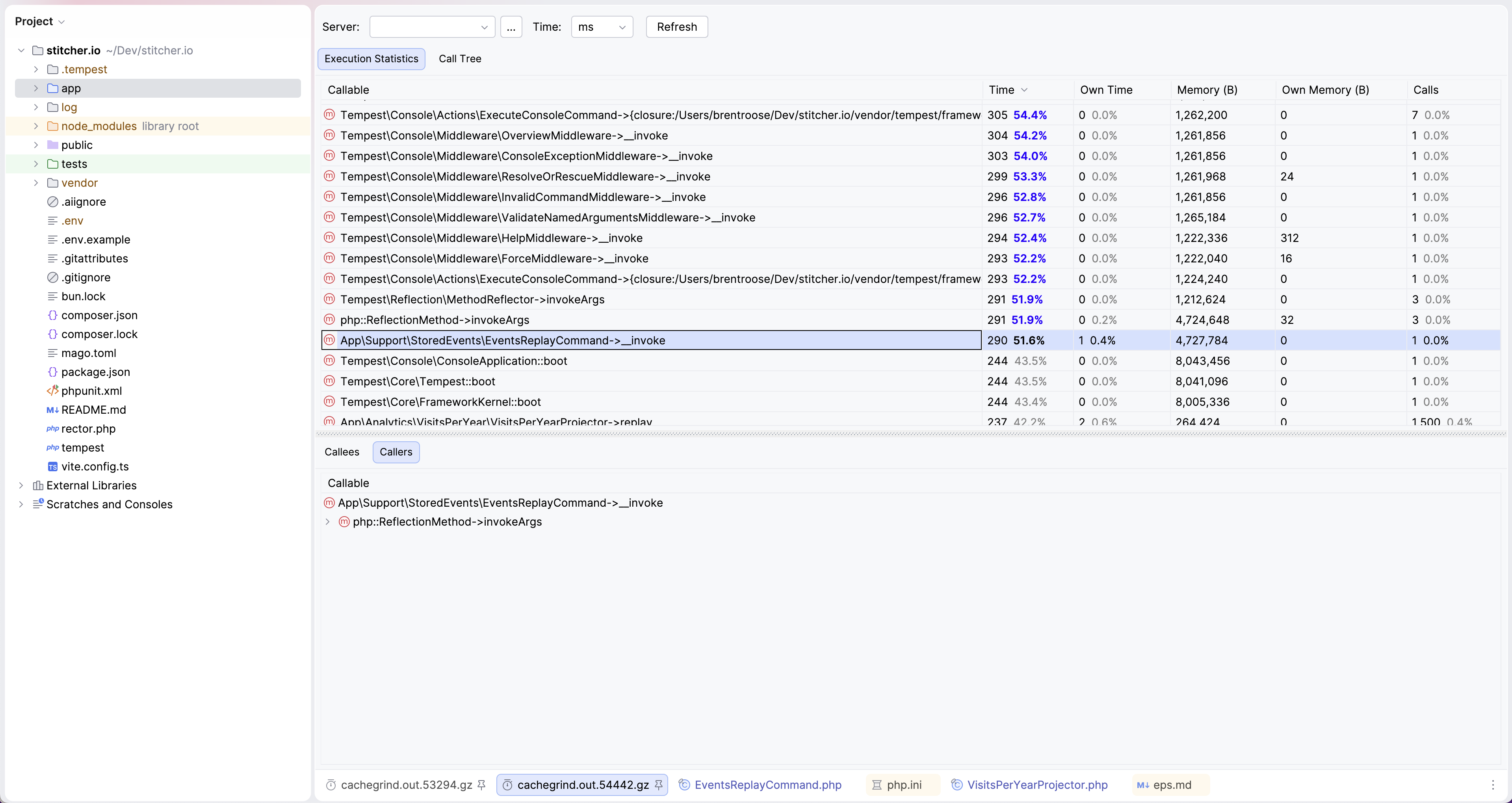
Optimizing the long-run
Another thing I noticed only when I ran the replay command for a longer time was that performance would slow down the longer the code ran. I was already tracking memory, which remained stable, so that wasn't the problem. After some thought, I realized it might have to do with the increasing $offset size on the query. So instead of using a traditional offset, I swapped it for the numeric (indexed) ID:
$lastId = 0; $limit = 1500; while ($data = query('stored_events')->select()->where('id > ?', $lastId)->limit($limit)->all()) { // … $lastId = array_last($data)['id']; }
This kept performance steady over time, which is rather important because our script will run for tens of minutes.
Buffered inserts
Another idea that someone on the Tempest Discord server mentioned was to buffer projector queries. Instead of sending query per query to the database server, why not buffer them for a while, and then send them in bulk. That wasn't too difficult to add either. I made the feature opt-in for now via an interface:
interface BufferedProjector extends Projector { public function persist(): void; }
Then I provided a trait that could be used by all buffered projectors:
trait BuffersUpdates { private array $queries = []; public function persist(): void { if ($this->queries === []) { return; } new Query(implode('; ', $this->queries))->execute(); $this->queries = []; } }
Next, I adjusted the projectors so that they didn't directly execute the query, but instead pushed it into the buffer:
#[EventHandler] public function onPageVisited(PageVisited $pageVisited): void { $hour = $pageVisited->visitedAt->format('Y-m-d H') . ':00:00'; $this->queries[] = sprintf( "INSERT INTO `visits_per_hour` (`hour`, `count`) VALUES (\"%s\", %s) ON DUPLICATE KEY UPDATE `count` = `count` + 1", $hour, 1 ); }
And finally, I made it so that the replay command would manually persist the buffer:
foreach ($projectors as $projector) { foreach ($events as $event) { $projector->replay($event); } if ($projector instanceof BufferedProjector) { $projector->persist(); } }
I was amazed to see that this change pushed performance from 14k to 19k events per second!
Finally satisfied, or am I?
At this point, I was pretty mind-blown with all the optimizations that I had made. However, would you believe me that I'd be able to more than double the throughput with just two lines of code?
On that same Discord server I mentioned earlier, Márk reached out to me. Now, Márk has been a very talented and loyal contributor to Tempest for over a year now. When Márk speaks, I tend to pay attention. Here's what he said:
What about... 👀 transactions to reduce fsync lag
Hmm, ok? What's that about, I asked.
So, if you don't do transactions InnoDB calls fsync() after every commit due to ACID (we are talking D here -> Durability). Without a transaction, every insert is an implicit commit, so 20k inserts = 20k commits = fsync() called 20k times. With an explicit transaction, it's... explicit. You can have 20k inserts in one transaction, when you commit it, that's gonna be 1 commit -> fsync() called once.
He ended by saying
Depending on the disk/CPU this operation can be quite meaningful
I was skeptical it would yield any meaningful results, but no harm in trying, right? After all, it's literally two lines of code to wrap the replay part in a transaction:
$this->database->withinTransaction(function () use ($projectors, $events) { foreach ($projectors as $projector) { foreach ($events as $event) { $projector->replay($event); } if ($projector instanceof BufferedProjector) { $projector->persist(); } } });
Do you want to make a guess as to how much improvement this made? We went from an already impressive 19k to… 45k events per second.
🤯
If I ever meet Márk face-to-face, I'm buying him a beer.
Finally satisfied
When I published this blog post yesterday, I assumed there were more improvements to be made. I wouldn't have guessed more than a doubling would be possible though. And who knows, maybe there's even more to be gained still?
Needless to say, I'm already very satisfied. I went from 30 to almost 50,000 events events per second. Rebuilding a single projector now takes a couple of minutes instead of 4–5 hours, an amazing improvement.
If you have any ideas on how to further improve it, you're welcome to join the Tempest Discord server or leave a comment!
Finally, all the code for this is open source. You can check of my blog's source code here, the analytics module is here, the dashboard itself is here, and it's of course all powered by Tempest.
Update: I've published a second part to this series, you can read it here.
